



【编者按:今天为大家带来的一份超全的超参数调优指南,可谓一文在手,超参数调优无敌手。本文主要介绍了超参数调优的基本概念、常用方法和算法,以及超参数调优的工具推荐。
小编温馨提示,全文阅读预计需要20-30分钟,可以先收藏哦!
话不多说,开启超参数调优之旅吧,Enjoy!】
作者 | Shahul ES, Aayush Bajaj
编译 | 岳扬
为机器学习或深度学习模型选择正确的超参数是从模型中提取精华的最佳方式之一。在本篇文章中,我们将向读者展示一些目前可用的做超参数调优的最佳方法。
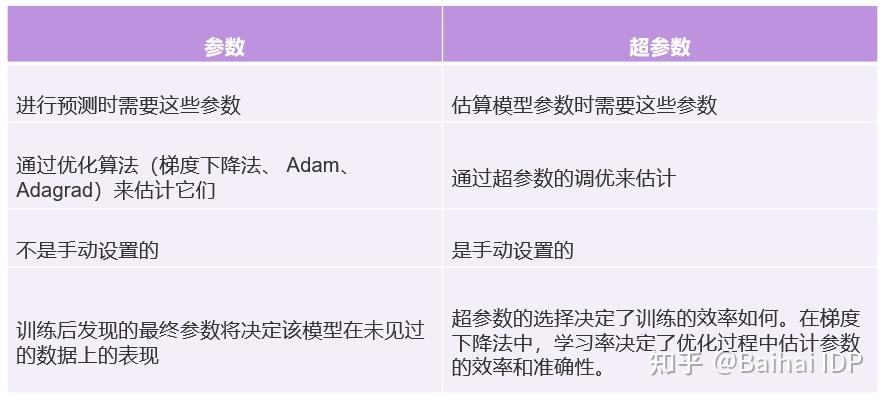
首先,让我们了解机器学习中超参数和参数之间的区别。
超参数调优[1](或超参数优化)是确定使模型性能最大化的超参数正确组合的过程。其在一个训练过程中运行多个试验。每一次试验都是训练程序的完整执行,并在指定的范围内选择超参数设置值。这个过程一旦完成,就会给你一组最适合模型的超参数值,以获得最佳结果。
毫无疑问,这是任何机器学习项目中的一个比较重要的步骤,因为其影响了模型的最佳结果。如果你希望看到超参数调优的作用,这里有一篇研究论文[2],通过在数据集上的实验,介绍了超参数优化的重要性。
选择正确的超参数组合需要拥有对超参数和业务用例的深刻理解。然而,从技术上讲,有两种方法来找到它们。
手动超参数调优包括通过手动方式来实验不同的超参数集。这种技术将需要一个强大的实验跟踪器,要能够跟踪从图像、日志到系统指标的各种变量。典型的提供试验追踪功能的工具包括Neptune, W&B、Comet或者MLflow。
手动超参数优化的优势
手动超参数优化的劣势
阅读关于如何手动优化机器学习模型超参数:How to Manually Optimize Machine Learning Model Hyperparameters - http://MachineLearningMastery.com
自动超参数调优是利用已有的算法来实现这一过程的自动化。需要遵循的步骤为:
在本节中,我将介绍当今流行的所有超参数优化方法。
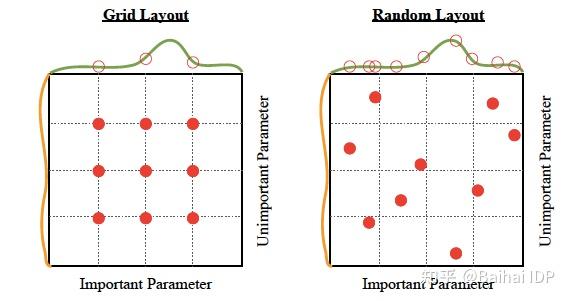
在随机搜索方法[4]中,我们为超参数创建了拥有很多可能值的网格。每次迭代都从这个网格中尝试随机的超参数组合,记录性能,最后得到最佳性能的超参数组合。
在网格搜索法中,我们为超参数创建了一个可能值的网格。每次迭代都以特定的顺序尝试超参数的组合。它在每一个可能的超参数组合上拟合模型并记录模型的性能。最后,它返回具有最佳超参数的最佳模型。
为模型调整和寻找合适的超参数是一种优化问题。我们希望通过改变模型参数来最小化我们模型的损失函数。贝叶斯优化帮助我们通过最少的步骤中找到最小的点。贝叶斯优化还使用了采集函数(Acquisition Funtion),将采样引向有可能比当前最佳观察结果更好的区域。
基于树的帕森优化的理念与贝叶斯优化很相似。TPE不是寻找p(y|x)的值——其中y是要最小化的函数(例如,验证损失),x是超参数的值,而是建立P(x|y)和P(y)的模型。TPE算法的一个很大的缺点是,它们没有对超参数之间的相互作用进行建模。尽管如此,TPE在实践中的效果非常好,并在大多数领域通过了实战检验。
这些是专门为超参数调优而开发的算法。
Hyperband是随机搜索的一个变种,但运用探索与利用理论[5],以便找到每个配置的最佳时间分配。你可以查看这篇研究论文[6],以获得进一步的参考。
这种技术是两种最常用的搜索技术的混合,同时将随机搜索和手动调整应用于神经网络模型。
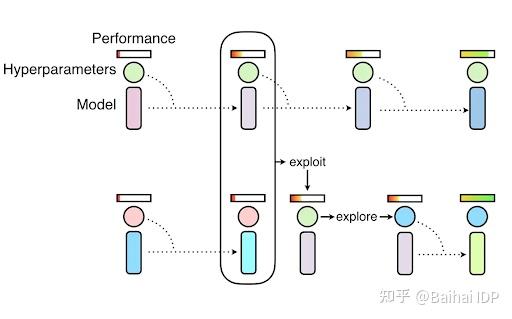
PBT首先用随机超参数并行训练多个神经网络,但是这些网络并不是完全相互独立的。其使用来自其他群体的信息来完善超参数,并确定要尝试的超参数值。你可以查看这篇文章[7],了解更多关于PBT的信息。
BOHB(Bayesian Optimization and HyperBand)混合了Hyperband算法和Bayesian优化。你可以查看这篇文章来进一步参考:https://www.automl.org/blog_bohb/。
Scikit-learn有网格搜索和随机搜索的实现,对于此两种方法,scikit-learn在不同的参数选择上,以K-fold交叉验证的方式训练和评估模型,并返回最佳模型。
具体来说:
用Scikit-learn调整模型是一个好的开始,但还有更好的选择,而且它们往往拥有随机搜索策略。
Scikit-optimize[8]使用一种基于序列模型的优化算法,在较短的时间内找到超参数搜索问题的最优解。
Scikit-optimize提供了除超参数优化之外的许多功能,例如:
Optuna使用过往记录的轨迹细节来确定有希望的区域来搜索优化超参数,从而在最短的时间内找到最佳超参数。
它具有修剪功能,可以在训练的早期阶段自动停止没有希望的轨迹。optuna提供的一些关键功能是:
在IDP中,可以快速开始使用Optuna。
Hyperopt允许用户创建一个搜索空间,在该空间中,用户期望得到最好的结果,使Hyperopt中的算法能够更有效地搜索。
目前,Hyperopt中实现了三种算法:
要使用hyperopt,首先应该确定:
教程(https://github.com/hyperopt/hyperopt/wiki/FMin)将指导你如何构建代码并使用hyperopt包来获得最佳的超参数。你也可以阅读这篇文章(https://mlwhiz.com/blog/2019/10/10/hyperopt2/)以了解更多关于如何使用Hyperopt的信息。
Ray Tune是在任何规模下进行实验和超参数调优的一个比较流行的选择。Ray利用分布式计算来加速超参数的优化,并为几种最先进的优化算法提供了规模化的实现。
Ray Tune提供的核心功能:
你可以参考这个教程(https://docs.ray.io/en/latest/tune/tutorials/overview.html)。
Keras Tuner可以为TensorFlow程序挑选最佳的超参数集。当建立一个用于超参数调优的模型时,除了模型架构外,还会定义超参数搜索空间。你为超参数调整所建立的模型被称为超模型。
你可以通过两种方法定义超参数模型:
你也可以将两个预定义的HyperModel类——HyperXception和HyperResNet用于计算机视觉应用。
你可以参考这个官方教程(https://www.tensorflow.org/tutorials/keras/keras_tuner),了解进一步的实施细节。
BayesianOptimization旨在最小化找到接近最优组合的参数组合所需的步骤数。
这种方法使用了一个代理优化问题(寻找获取函数的最大值),虽然它仍然是一个比较困难的问题,但在计算意义上花费更小,而且可以采用普通工具。因此,贝叶斯优化法最适合于对要优化的函数进行采样比较昂贵的情况。
请访问GitHub repo(https://github.com/fmfn/BayesianOptimization),看看它的当前情况。
MOE(Metric Optimization Engine)是在评估参数耗时多或代价昂贵的情况下优化系统参数的一种有效方法。
它非常适合于以下问题 :
这种处理黑箱目标函数的能力使我们能够使用MOE来优化几乎任何系统,而不需要任何内部知识或内部权限。
请访问GitHub Repo(https://github.com/Yelp/MOE)以获得更多信息。
Spearmint被设计为自动运行实验(因此被命名为spearmint),其方式是迭代调整一些参数,以便在尽可能少的运行中使一些目标最小化。
在这个GitHub repo(https://github.com/HIPS/Spearmint)中阅读有关Spearmint的内容。
GPyOpt是使用GPy的高斯过程优化。其使用不同的采集函数(Acquisition Functions)进行全局优化。
可以使用GPyOpt来优化物理实验(按顺序或分批),并调整机器学习算法的参数。它能够通过稀疏的高斯过程模型处理大型数据集。
不幸的是,GpyOpt已经停止维护,但你仍然可以使用该软件包进行实验。
其GitHub repo:https://github.com/SheffieldML/GPyOpt。
SigOpt将自动超参数调优与训练运行跟踪完全整合在一起,让你对整体和达到最佳模型的路径有一个基本的认识。
凭借高度可定制的搜索空间和多指标优化等功能,SigOpt可以在将你的模型投入生产之前,通过简单的API进行复杂的超参数调优。
访问这里的文档(https://app.sigopt.com/docs/intro/intelligent_optimization),了解更多关于SigOpt。
传统的贝叶斯超参数优化器将机器学习算法在给定数据集上的损失建模为需要最小化的黑箱函数,而Fast Bayesian Optimization on LArge data Sets (FABOLAS)则在不同的数据集大小上为损失和计算成本建模,并使用这些模型来进行具有额外自由度的贝叶斯优化。
你可以在这里查看实现fabolas的函数(https://github.com/automl/RoBO/blob/master/robo/fmin/fabolas.py#L31)和研究论文(https://arxiv.org/pdf/1605.07079.pdf)。
参考资料
原文:https://neptune.ai/blog/hyperparameter-tuning-in-python-complete-guide
在线客服
客服咨询


官方微信
返回顶部

