



CV调包侠自己的深度学习交流群中一位兄弟在看我以前的github和博客:https://blog.csdn.net/qq_46098574/article/details/107334954 中,跑完项目,发现效果较差,不尽人意,然后想知道如何提高评价指标和优化,因为Yolov5 的速度和精度是及其优秀的,很多人就想着优化,并且能以此为baseline 落地一些实时性项目。我昨天想了一下,做了第一次的模型优化,后续我还会做更多优化,关注一下,下次做完继续开源。公众号回复:yolov5香烟领取数据+模型+导出+Openvino推理,参考Github:https://github.com/CVUsers/Smoke-Detect-by-YoloV5

实际检测演示:



除去误检(误检解决方案请看后文优化策略) 1米之内效果不错,3-5米之内效果可以接受。
以前面项目中的模型训练为例子:香烟检测,属于一个小目标检测
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u0ApNqtU-1605412929251)(D:\CSDN\pic_new\v5优化\1605358340578.png)]](https://img-blog.csdnimg.cn/20201115120536242.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
? 数据预处理与数据整理上,我将原数据中部分因标注问题,最终导致labels出错的问题解决,注意,要是labels为空,那么会将这个带有香烟的图片当作“负例”,参与一种模型泛化,但是不会得到数据中的香烟特征,可以简单的认为对我们香烟检测无意义。你可以简单的写个脚本判断他的xml中的数据是否为空,然后写入,出现labels为空的问题,实际上是对XML To Labels 的逻辑错误,大家看看源码Debug一下就知道啦~
踩坑Tips1:数据转换:xml转labels :数据标注中xml有一个叫folder 路径:有中文可能因为Gbk无法解析,可以尝试用gbk打开xml,或者是写个脚本将xml中的folder改成英文;
? labels出现空,可能是因为标注中类别不存在,问题,修改一下数据标注的class就行
正如上述,使用空lebels会稍微带来一些泛化,那么我们可以使用大量的实际场景背景做空labels,大家可以实际测试一下,可能评价指标不会上升一些,但是实际情况可以测试一下,我在火箭军比赛中,一种优化策略是如此使用空标签训练,效果是有的,cv调包侠认为还是看数据的,我比赛数据特殊 ,在这个香烟检测项目中,数据量是5000张标注数据 ,在项目中算正常量的数据,在实际场景中算少,需要10w张以上。那么使用空标签方案值得一试。不过可能效果不大。
看到这么多配置参数,大家可以尝试使用evolve, multi-scale做优化。
在Anchor上,我一位好朋友,波哥有自己的见解,大家可以看这篇,顺便三连一下波哥的文章,Anchor上计算的优化。见https://blog.csdn.net/aabbcccddd01/article/details/109578614
yolo3中的锚框是预先利用kmeans定义好的,yolo4沿用了yolo3;
yolo5锚定框是基于训练数据自动学习的。个人认为算不上是创新点,只是手动改代码改为自动运行。
对于COCO数据集来说,YOLO V5 的配置文件*.yaml 中已经预设了640×640图像大小下锚定框的尺寸:
对于自定义数据集来说,由于目标识别框架往往需要缩放原始图片尺寸,并且数据集中目标对象的大小可能也与COCO数据集不同,因此YOLO V5会重新自动学习锚定框的尺寸。
Yolov5自带在线数据增强,也就是说,每个Epoch中的数据,都是经过数据增强后的,实现一个泛化能力,我们来看原本的在线增强参数:
比如将左右翻转打开,马赛克增强打开,mixup也打开,以及hsv的改变,值得注意的是,YOLO V4使用了多种数据增强技术的组合,对于单一图片,使用了几何畸变,光照畸图像,遮挡(Random Erase,Cutout,Hide and Seek,Grid Mask ,MixUp)技术,对于多图组合,作者混合使用了CutMix与Mosaic 技术。除此之外,作者还使用了**Self-Adversarial Training (SAT)**来进行数据增强。
YOLOV5会通过数据加载器传递每一批训练数据,并同时增强训练数据。数据加载器进行三种数据增强:缩放,色彩空间调整和马赛克增强。据悉YOLO V5的作者Glen Jocher正是Mosaic Augmentation的创造者,故认为YOLO V4性能巨大提升很大程度是马赛克数据增强的功劳,也许你不服,但他在YOLO V4出来后的仅仅两个月便推出YOLO V5,不可否认的是马赛克数据增强确实能有效解决模型训练中最头疼的“小对象问题”,即小对象不如大对象那样准确地被检测到。
这个数据增强要根据不同的数据集做的增强的。V5 的在线数据增强比较优秀,虽然我还自己添加了其他增强算法,但是大家可以很快的在原代码中找到数据增强的地方。
另一个数据增强的优化策列就是用Gans或者自己写个抠图脚本,把boxes区域的信息抠出来,掩码贴到其他图片中,或者贴到图片中的其他地方。
请注意语义和逻辑:也就是,比如香烟检测,尽量不要贴到与实际意义不大的背景和区域,怎么说也要贴到手上吧。
通常中,与语义无关的,可以使用这个方案获取大量的数据,而且我们知道boxes区域,可以写个脚本自动生成标注集:XML, 像我们火箭军中的数据是与语义关联不大的,就使用了这样的增强策略。
说优化,其实首要的第一步就是换模型,大家看Yolo的发布者就知道,Yolo现在一共有3个版本,Cv调包侠上一个博客
https://blog.csdn.net/qq_46098574/article/details/107334954 是Yolov5刚出来两天就跑通了的,属于第一个版本,简称V1版,大家自行比较一下:
1.0版本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QhSYUVWZ-1605412929256)(D:\CSDN\pic_new\v5优化\1605402044072.png)]](https://img-blog.csdnimg.cn/20201115120633323.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
V2.0版本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0SKHpyfW-1605412929258)(D:\CSDN\pic_new\v5优化\1605402104852.png)]](https://img-blog.csdnimg.cn/20201115120642282.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
V3.0版本

其中V3 版本是其中最优秀的(其实也就好了一些)
所以我推荐使用V3 版本,V3中也有一个更新使用LeakyRelu激活函数的V2也是使用LeakyRelu激活函数的,我们需要推理优化嵌入部署,就需要将Pytorch模型转成Onnx等, 由于onnx和openvino 还不支持 Hardswitch,要将 Hardswish 激活函数改成 Relu 或者 Leaky Relu。 于是我们选择了V2版本来训练以及导出。
模型训练和其他步骤,大家可以看我上一篇博,Yolo训练比较简单,有问题可以咨询我。
YOLO V5和V4都使用CSPDarknet作为Backbone从输入图像中提取丰富的信息特征。CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,具体做法是:将梯度的变化从头到尾地集成到特征图中,减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。

CSPNe思想源于Densnet,复制基础层的特征映射图,通过dense block 发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主要有CSPResNext50 and CSPDarknet53两种改造Backbone网络。
YOLO V5和V4都使用PANET作为Neck来聚合特征。Neck主要用于生成特征金字塔,增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。
在PANET之前,一直使用FPN(特征金字塔)作为对象检测框架的特征聚合层,PANET在借鉴 Mask R-CNN 和 FPN 框架的基础上,加强了信息传播。
PANET基于 Mask R-CNN 和 FPN 框架,同时加强了信息传播。该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3x3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息。同时使用自适应特征池化(Adaptive feature pooling)恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配。
模型Head主要用于最终检测部分,它在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。yolo5在通用检测层,与yolo3、yolo4相同。
最后三个特征图是不同缩放尺度的Head被用来检测不同大小的物体,每个Head一共(80个类 + 1个概率 + 4坐标) * 3锚定框,一共255个channels。
yolo4和yolo5基本相同的网络架构,都使用CSPDarknet53(跨阶段局部网络)作为Backbone,并且使用了PANET(路径聚合网络)和SPP(空间金字塔池化)作为Neck,而且都使用YOLO V3的Head。YOLO V5 s,m,l,x四种模型的网络结构是一样的。原因是作者通过两个参数分别控制模型的深度以及卷积核的个数。
yolo5的作者使用了 Leaky ReLU 和 Sigmoid 激活函数。yolo5中中间/隐藏层使用了 Leaky ReLU 激活函数,最后的检测层使用了 Sigmoid 形激活函数。而YOLO V4使用Mish激活函数。
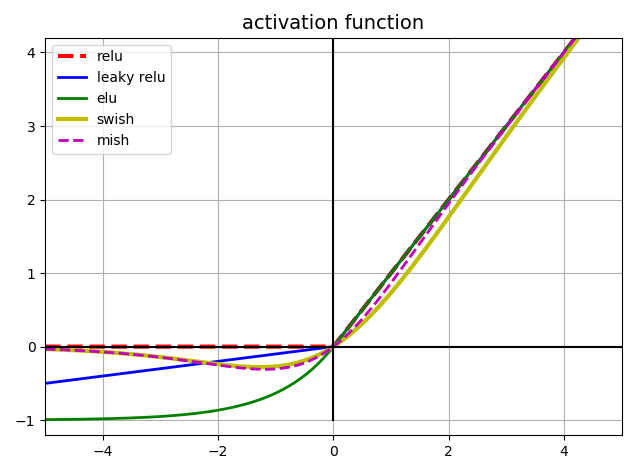
YOLO V5的作者提供了两个优化函数Adam和SGD(默认),并都预设了与之匹配的训练超参数。
YOLO V4使用SGD。
YOLO V5的作者建议是,如果需要训练较小的自定义数据集,Adam是更合适的选择,尽管Adam的学习率通常比SGD低。但是如果训练大型数据集,对于YOLOV5来说SGD效果比Adam好。
实际上学术界上对于SGD和Adam哪个更好,一直没有统一的定论,取决于实际项目情况。
YOLO 系列的损失计算是基于 objectness score, class probability score,和 bounding box regression score.
YOLO V5使用 GIOU Loss作为bounding box的损失。
YOLO V5使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时我们也可以使用fl _ gamma参数来激活Focal loss计算损失函数。
YOLO V4使用 CIOU Loss作为bounding box的损失,与其他提到的方法相比,CIOU带来了更快的收敛和更好的性能。
YOLO V5的训练非常迅速,在训练速度上远超YOLO V4。对于Roboflow的自定义数据集,YOLO V4达到最大验证评估花了14个小时,而YOLO V5仅仅花了3.5个小时。
V5x: 367MB,V5l: 192MB,V5m: 84MB,V5s: 27MB,YOLOV4: 245 MB
YOLO V5s 模型尺寸非常小,降低部署成本,有利于模型的快速部署。
在单个图像(批大小为1)上,YOLOV4推断在22毫秒内,YOLOV5s推断在20毫秒内。而YOLOV5实现默认为批处理推理(批大小36),并将批处理时间除以批处理中的图像数量,单一图片的推理时间能够达到7ms,也就是140FPS,这是目前对象检测领域的State-of-the-art。我使用我训练的模型对10000张测试图片进行实时推理,YOLOV5s 的推理速度非常惊艳,每张图只需要7ms的推理时间,再加上20多兆的模型大小,在灵活性上堪称无敌。但是其实这对于YOLO V4并不公平,由于YOLO V4没有实现默认批处理推理,因此在对比上呈现劣势,接下来应该会有很多关于这两个对象检测框架在同一基准下的测试。其次YOLO V4最新推出了tiny版本,YOLO V5s 与V4 tiny 的性能速度对比还需要更多实例分析。
总的来说,YOLO V4 在性能上优于YOLO V5,但是在灵活性与速度上弱于YOLO V5。我个人觉得对于这些对象检测框架,特征融合层的性能非常重要,目前两者都是使用PANET,但是根据谷歌大脑的研究,BiFPN才是特征融合层的最佳选择。谁能整合这项技术,很有可能取得性能大幅超越。
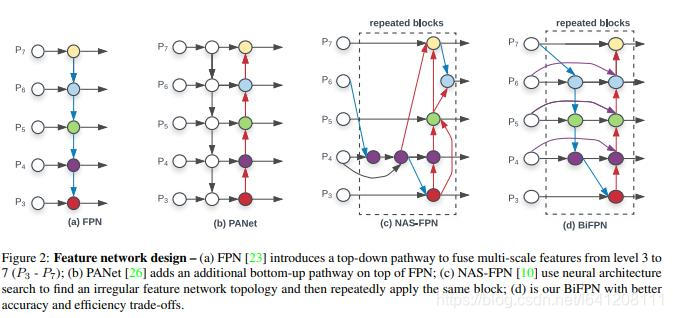
尽管YOLO V5目前仍然计逊一筹,但是YOLO V5仍然具有以下显著的优点:
其实很多人都觉得YOLO V4和YOLO V5实际上没有什么耳目一新创新,而是大量整合了计算机视觉领域的State-of-the-art,从而显著改善YOLO对象检测的性能。其实我觉得有的时候工程应用的能力同样也很重要,能有两个这么优秀的技术整合实例供我们免费使用和学习研究,已经不能奢求更多了,毕竟活雷锋还是少啊。先别管别人谁更强,自己能学到更多才是最重要的,毕竟讨论别人谁强,还不如自己强。
最后想说的是,技术发展如此之快,究竟谁能最后拿下最佳对象检测框架的头衔尤未可知,而我们处在最好的时代,让我们且行且学且珍惜。
记小本本啦!
在香烟检测中,我是以前说过我是项目级别的,不是面向落地应用的,我的初衷是校园(包含不局限于)异常行为检测监听项目,涵盖各种异常检测,使用Yolo的话,我是考虑实时性。但是面向落地应用,会使用跳帧抽帧检测,的方式来落地,就是说不必须要30FPS ,我后续也可能会面向落地,使用优质的小目标检测算法做Baseline,
优化策略:切割训练,二重检测方法(面向企业项目级和落地级别)
分别检测脸部和手部,模型融合,再使用切割后的脸部吸烟以及手部持烟数据集训练,推理的时候就是先检测脸部或手部,检测到后二次检测烟(这里准确率会很高,误检很低),若是检测不到脸部,手部就用原来的方案,在二重检测中,要是再使用目标检测算法检测,若是考虑实时性,那么我建议使用轻量级分类网络做判别。速度会稍快。
正如上文说到Yolo没有负样本概念,我们前面使用空标签得到泛化的提升,那么我们可以进一步针对误检进行优化:
**很多朋友在问:你的香烟检测会不会把笔和筷子,牙签检测误检成香烟,这是我们需要避免的问题(虽然我现在的模型就不会),但是还是多少会出现其他相似物体的误检,那么我们就可以进行一个优化,我们可以新增一个类别或者多个类别进行训练误检的物体,让他们成为负样本。这样拿去训练,一定会对正样本起到更好的效果**我最近也在优化模型,不过由于时间紧张,我的速度不是很快,因为我还有实习等等任务,业余完善异常检测即可,大家可以到我公众号拿数据,也可以分享数据给我
模型转换大家可以看我朋友的这篇文章:https://mp.weixin.qq.com/s/DdsxyGAatsOXGXVMgE9DfQ
1 在 Ubuntu 上安装 OpenVINO 开发工具
下载安装包 2020年4月的 linux 版本
2 安装依赖?
3 建立虚拟环境
Python>=3.8,PyTorch==1.5.1,ONNX>=1.7。
4 导出在 pytorch 上训练好的 yolov5 模型,公众号回复 Yolov5香烟 领取源码和模型和数据

先下载 yolov5s.pt(或者训练自有数据集的yolov5模型),放入目录下
要下载 v2.0 with nn.LeakyReLU(0.1) 的版本,因为 3.0 的 nn.Hardswish 还没有被支持。
5 修改激活函数
由于onnx和openvino 还不支持 Hardswitch,要将 Hardswish 激活函数改成 Relu 或者 Leaky Relu。
6 修改 yolo.py
修改输出层堆叠,不包含输入层
7 修改 export.py
因为版本为10的 opset 能支持 resize 算子,要修改 opset 版本号。
? Tip
务必确保 torch1.15.1,torchvision0.6.1,onnx==1.7,opset=10。激活函数为 Relu,并修改了网络推理层。
*将 pt --> onnx*
* *
*
显示导出为 onnx 和 torchscript 文件即可。
我的Onnx模型以及导出了,大家可以公众号回复:yolov5香烟 领取

9 将 onnx --> ir
顺利的话,就能在 out 目录下生成 yolov5s 的 IR 模型了,接着将文件传输到树莓派上。
? Tip
这里要匹配 yolov5s 的 input shape 为 [ 1, 3, 640, 640 ]。
10 修改参数匹配训练模型
修改推理设备和输入 shape
修改类别信息
修改多类别输出(如果需要)
11 推理输出
就可以推理了~
推理速度和精度,在CPU下还是不尽人意。正如明成哥文章中说到(基于Yolov5m, 和S):
这里 模型压缩裁剪量化我还没有成功实现,难度是有的,还没到落地阶段,我也没有仔细研究,但是Cv调包侠分享一个Tips,为啥我训练出来的模型有的比较大呢?如何压缩模型,让他减小一些呢?大家仔细观察应该是有这个发现的,正如Cv调包侠公众号回复:yolov5香烟里面的模型文件就是v5s的模型,正常应该是23mb左右,为啥训练出来的是40多mb呢?

精度变化
官方给的预训练权重是FP16,而我们训练的时候是使用混合精度训练(支持CUDA才行),半精度训练只能在CUDA下进行,不支持CUDA默认是使用单精度训练,最终我们保存的权重是FP32,较FP16储存空间大了一倍。直接上代码视图:
原始预训练权重

我们自己的训练权重

参数储存不同
预训练权重默认epoch=-1,不保存training_results,不保存optimizer,相当于只保存了模型和权重
可以用以下代码测试以下


我们训练的时候是默认都保存,源码设置的是在最后一个批次不保存optimizer,如果你是正常跑完所有epoch,最后的权重应该是不包含optimizer,否则会自动保存,以下是官方train.py的保存权重的部分代码

由于CV调包侠训练了255个迭代就拟合了,没训练完,所以保存了Otimizer,所以我们自己训练出来的模型权重文件比较大是必然的
那问题来了,如果想让权重文件变小怎么办
[注]小编此处使用的权重是基于yolov5s预训练权重训练后的结果,且未在批次执行完就停止,也就是这个权重默认是包含以下这么多信息,内容较多,暂且用省略号表示
初始大小为:57M

现在我一步步来让这个权重变小
step1
第一步按照以下内容进行,为什么epoch变成-1,官方权重设置的epoch为-1,作为预训练权重,批次从0开始,如果仅作为inference权重,这个不影响;接着是把training_results变为None
我们按照以上内容把权重文件重新保存以下看看大小变化多少,如下图所示,发现这个training_results占的内存很少,基本可以忽略不计:

step2
第二步按照以下内容执行,相比第一步,只是把optimizer参数变成None
这次权重又有多大变化呢,如下图所示,发现这个optimizer占的内存很多,大致占了权重文件的一般大小,说明优化器的参数是导致文件较大的主谋:

step3
可是权重文件还是很大,比原始的yolov3s大了一倍,这是因为目前的权重还是FP32,需要把FP32转为FP16,此处根据个人情况来决定是否转为FP16,小编不才,此处使用暴力方法直接把FP32转FP16(使用half函数),如下图,权重小了一倍,基本和yolov3s大小差不多。

以下把代码附上,很简单
我已经导出了,大家下载就能看到~
? ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7uhD4NRF-1605412929268)(D:\CSDN\pic_new\v5优化\1605412850448.png)]](https://img-blog.csdnimg.cn/20201115121012336.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
最后 欢迎关注公众号,获取数据集+模型+代码+作者联系方式+深度学习交流群~

在线客服
客服咨询


官方微信
返回顶部

