



质数(素数):只能被1和其本身整除的数字(其中1和0不属于质数)
接下来我们用多种方法求1000以内(包含1000)的质数数量,并且统计每种方法的循环次数
(如果只想知道速度快的方法可以直接看方法五)
循环遍历所有情况
此时总循环次数为498501次
质数个数有168个
改进点: 当一个数第一次被比自己小的数(不包含1)整除成功后,我们就可以立刻判断出这个数不是质数,所以我们使用break跳出循环,结束对这个数接下来的判断
此时总循环次数为78022次
质数个数有168个
改进点: 如果存在数字1能被数字2整除,那么一定存在这样一个小于等于数字1算术平方根的数字2(数学定理),所以一个数字在2~本身算术平方根这个数字区间内没有遇到能够被整除的数字,那么这个数就不是质数
简单解释一下:因数都是成对出现的。比如,100的因数有:1和100,2和50,4和25,5和20,10和10。看出来没有?成对的因数,其中一个必然小于等于100的开平方,另一个大于等于100的开平方。
注释掉的部分可以进一步提高计算速度,但提高不是非常大
此时总循环次数为5288次
质数个数有168个
改进点: 如果数字1取余数字2不等于0,那么数字一取余数字2的倍数一定也不为0。
例如:7%2!=0那么我们没必要再去算7%4和7%6,因为4=22,6=32
所以,我们只需要判断一个数是否能被小于他的质数除尽即可
在这里我们将已经算出来为的质数存到一个数组中,后续的%只需对该数组中小于这个数本身平方根的数字进行
此时总循环次数为3467次
质数个数有168个
此时总循环次数为1956次
质数个数有168个
讲解: 利用了筛法,首先,2是公认最小的质数,所以,先把所有2的倍数去掉;然后剩下的那些大于2的数里面,最小的是3,所以3也是质数;然后把所有3的倍数都去掉,剩下的那些大于3的数里面,最小的是5,所以5也是质数……
上述过程不断重复,就可以把某个范围内的合数全都除去(就像被筛子筛掉一样),剩下的就是质数了。维基百科上有一张很形象的动画,能直观地体现出筛法的工作过程。
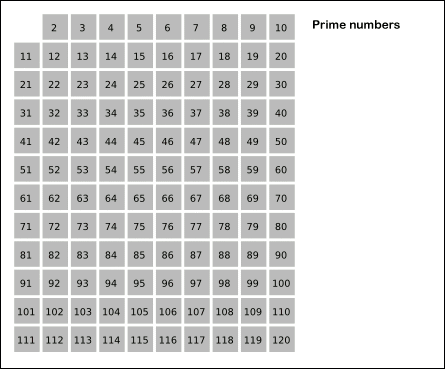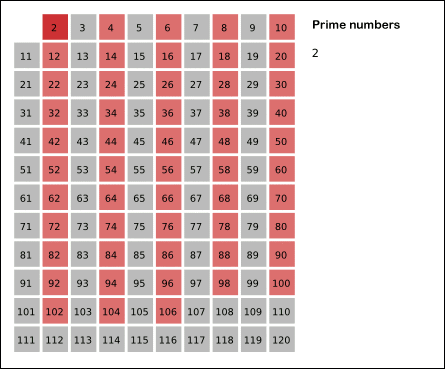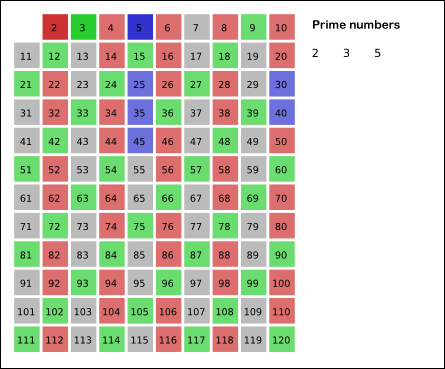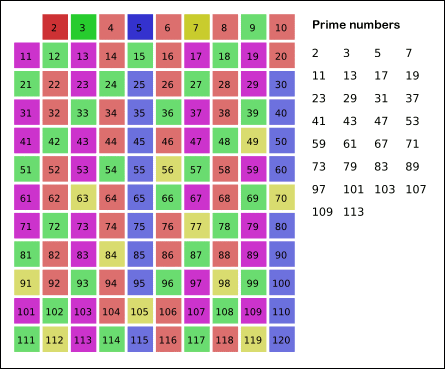
现在是让你求1000以内的素数,我们可以写死让i<=1000,但如果题目改为让你按从小到大的顺序,输出1000个质数该怎么办呢?第1000个质数的范围在哪里呢?
如果我们使用上面的方法四可以这样写
但是我们知道方法四比方法五要慢很多,但方法五中我们是提前定好了boolean prime[] = new boolean[1001];,第一千个质数我们应该将prime[]的大小定位多少呢?
这就涉及到了我们的数学知识, 数学家找到了一些公式,用来估计某个范围内的素数,大概有几个。在这些公式中,最简洁的就是 x/ln(x),公式中的 ln 表示自然对数(估计很多同学已经忘了啥叫自然对数)。假设要估计1,000,000以内有多少质数,用该公式算出是72,382个,而实际有78,498个,误差约8个百分点。该公式的特点是:估算的范围越大,偏差率越小。
有了素数定理,就可以根据要打印的质数个数,反推出这些质数分布在多大的范围内。因为这个质数分布公式有一定的误差(通常小于15%)。为了保险起见,把反推出的素数分布范围再稍微扩大15%,应该就足够了。
看到这你因为这已经是最优的解法了吗?不,现在我们只优化了时间,还没有优化空间。
有些程序猿会想出按位(bit)存储的思路。
以Java为例。一个boolean占用4字节内存(boolean类型占了单独使用是4个字节,在数组中又是1个字节)。而1个字节有8个比特,每个比特可以表示0或1。所以,当你使用按位存储的方式,一个字节可以拿来当8个布尔型使用。所以,构造一个定长的byte数组,数组的每个byte存储8个布尔值。空间性能相比直接定义boolean,提高8倍(对于Java而言)。
关于代码优化这件事,我认为没有最优,只有更优,科技永远不会停下前进的脚步
在线客服
客服咨询


官方微信
返回顶部

